Feature Importance With XGBoost in Python
XGBoost is one of the most popular and effective machine learning algorithm, especially for tabular data. Once we've trained an XGBoost model, it's often useful to understand which features were most important to the model. This allows us to gain insights into the data, perform feature selection, and simplify models.
As a machine learning scientist/engineer, it is important to understand your dataset. Without understanding the dataset, it is hard to debug the quality of machine learning models built with it.
These are the reasons why feature importance is important for any machine learning practitioner.
- Feature selection: Feature importances allow us to select the most relevant features to train our models on. Less relevant features can be removed to reduce noise and improve performance. This is especially useful for high-dimensional datasets.
- Model interpretation: Understanding which features drive the model's predictions is crucial for model interpretability. We can better understand the patterns and relationships learned by the model.
- New insights: Examining feature importances can provide new insights into the relationships and dynamics in our data. Features we didn't realize were important may emerge.
- Domain knowledge: The feature importances may reveal that the model relies heavily on features that don't match expert domain knowledge. This could indicate issues with the data or modeling process.
- Data collection: Knowing the most important features can guide what data is collected. Resources can be focused on collecting useful data inputs for the model.
- Complexity reduction: Less important features can be removed to simplify and streamline complex models like XGBoost ensembles. This can improve efficiency and performance.
In the context of XGBoost, feature importance is calculated based on the amount that each attribute split point improves performance measure, weighted by a number of times the feature is selected for a split in a tree. Some of the ways to measure feature importance are
- Split count: The number of times a feature is selected for a split in a tree.
- Cover: The number of observations in the training set that a node had split. Specifically, for every feature j, Cover is the total number of observations in splits that involve this feature.
- Gain or the decrease in impurity: For every feature j, Gain is the sum of the squared difference between the parent node impurity and the child node impurities.
Luckily, XGBoost has built-in support for calculating feature importance. There are two main methods:
- Feature Importance From Model Object
We can extract feature importances directly from a trained XGBoost model using "feature_importances_". Here is an example:
import xgboost as xgb
# Train XGBoost model
model = xgb.XGBClassifier()
model.fit(X_train, y_train)
# Get importance
importance = model.feature_importances_
# Sort importance
indices = np.argsort(importance)[::-1]
# Print top 10 most important features
for f in range(10):
print("%d. feature %d (%f)" % (f + 1, indices[f], importance[indices[f]]))
This will print out the top 10 most important features based on the model.
- Feature Importance From Evaluation Metric
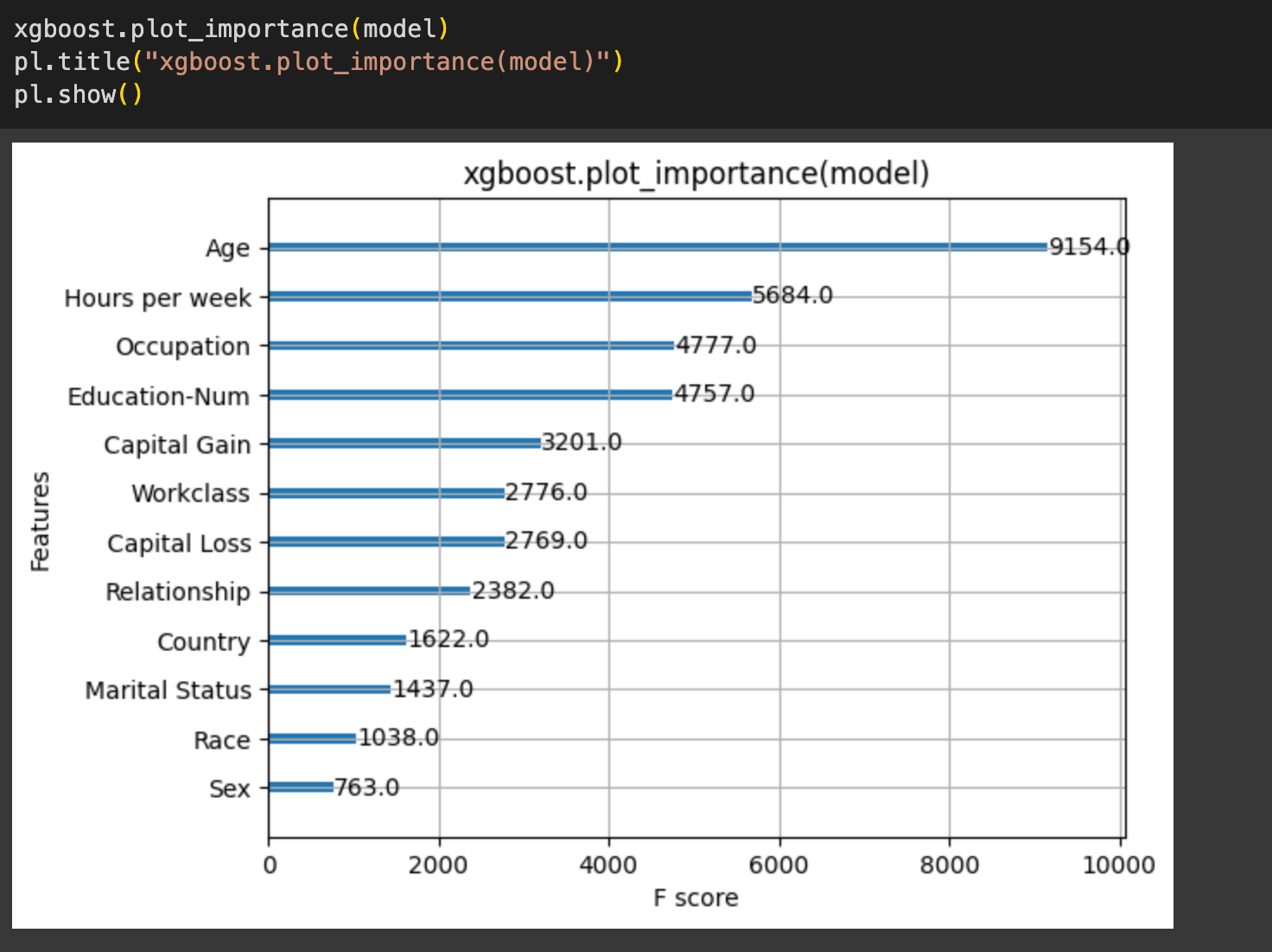
We can also calculate feature importance using the xgboost.plot_importance() function. This uses a different algorithm based on the gain achieved from splits on each feature:
import xgboost as xgb
# Train model
model = xgb.train(params, dtrain)
# Plot importance
xgb.plot_importance(model)
This will produce a plot showing the relative importance of each feature.
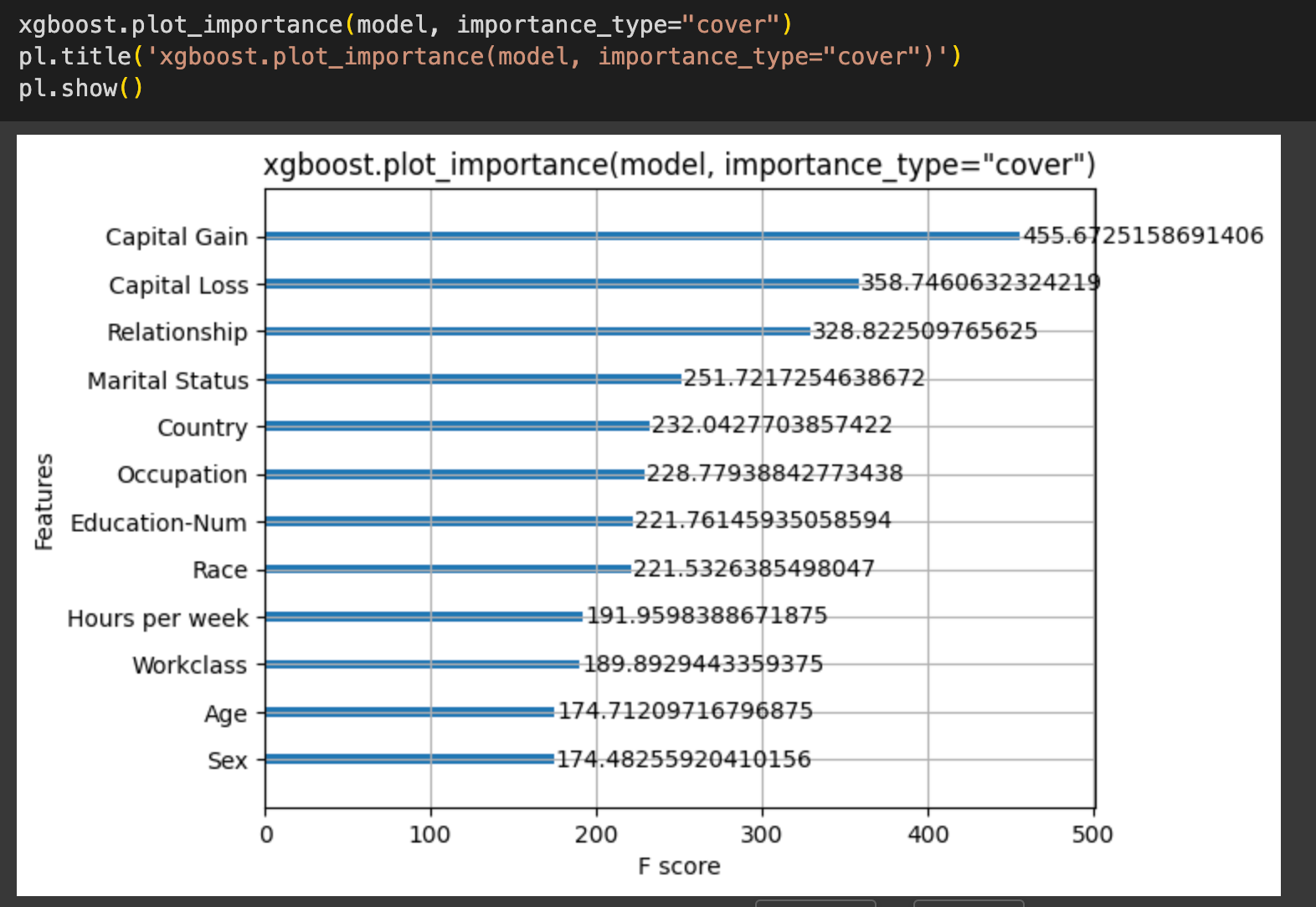
There are few other types of importance as well
- importance_type="cover". calculates the feature importance based on the average coverage across all splits the feature is used in.
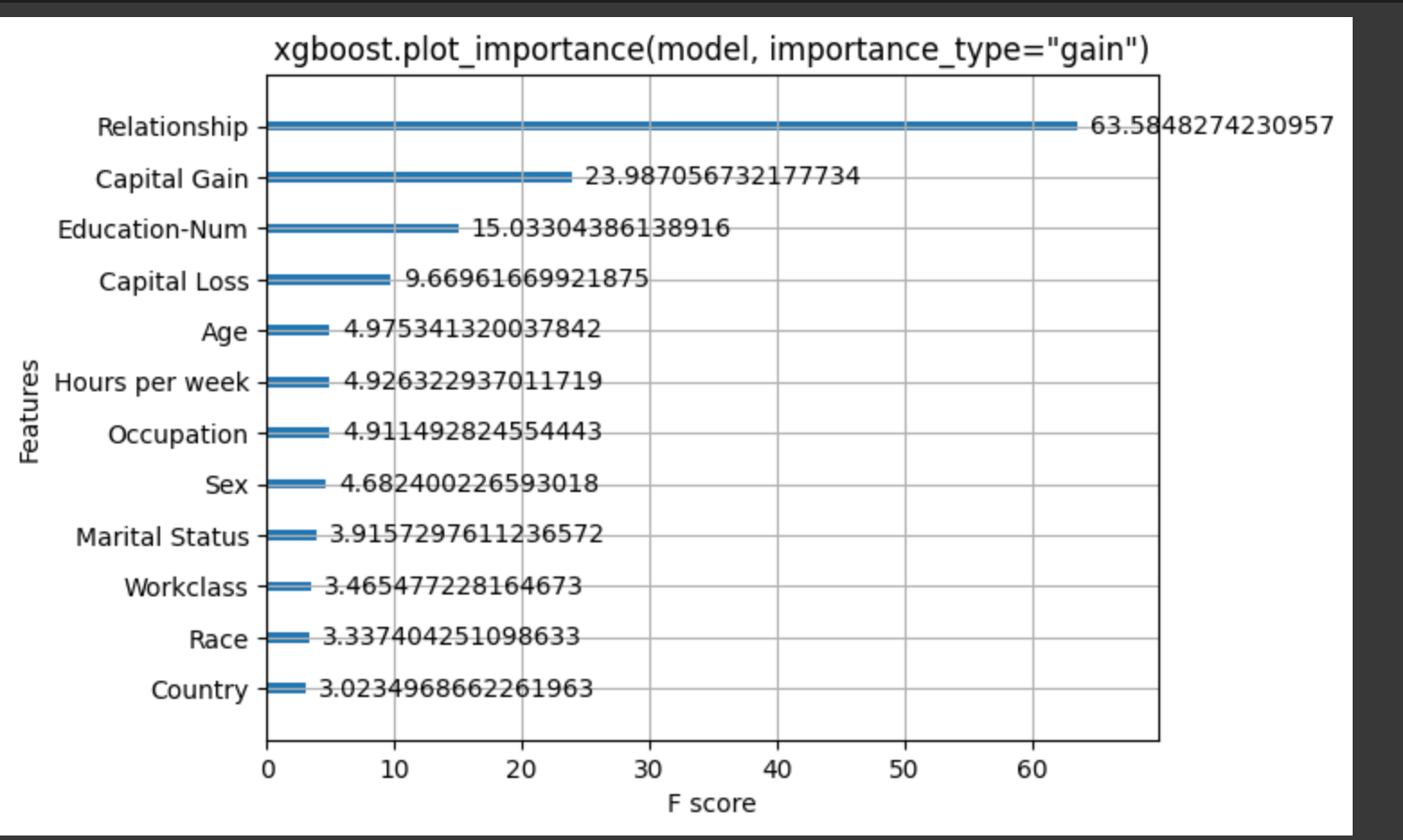
- importance_type="gain". This refers to the difference in error before and after splitting the data on a particular feature value. A higher gain score means the split leads to a more significant improvement in predicting the target variable.
In summary, XGBoost makes it easy to extract feature importances to better understand our models and data. The two main methods are extracting importance directly from the model object, and using the xgboost.plot_importance() function. Feature importances can help guide feature engineering and selection to improve models.
Differences between SHAP feature importance and the default XGBoost feature importance
Interpretation:
- XGBoost feature importance: Indicates how useful or valuable each feature was for the model's predictions. Importance is calculated by the number of times a feature is split on across all boosted trees.
- SHAP: Explains how each feature contributes to the prediction for every single data point. It tells you the impact of features on an individual prediction.
Calculation Method:
- XGBoost: Feature importance is encoded directly into the model based on number of splits.
- SHAP: Calculates importance scores using a game theoretic approach based on Shapley values from coalitional game theory.
Granularity:
- XGBoost feature importance is global - a single importance score assigned to each feature
- SHAP provides local feature importance - each data point gets a custom set of importance scores for interpretability.
Model-agnostic:
- XGBoost feature importance tailored specifically to XGBoost models
- SHAP can be used to explain predictions from any machine-learning model
References